TUMCTF Teaser 2015: Misc 200 "Autoaggressive Desensitization" writeup
Extract some RTP data and find the flag in the lofty frequencies above some growling cats.
For veterans:
- flag is hidden in the RTP data, extract raw data with Wireshark’s RTP stream reader
- import as raw data into
audacity, parameters: Signed 16 bit PCM, big endian, stereo, 44100Hz - look at the spectrum with
sox, or withspek(but you will need some zoom adjustments) - the high frequency peaks (above 8kHz) represent bits, the flag is encoded in 8bit ASCII
- method 1: read it directly from the spectrogram, tweak around brightness/contrast if needed to make the spikes discernible
- method 2: apply very hard -48dB high pass filter, cut off below 8.25kHz, the amplitudes should be clear low and high peaks now
- the flag is:
hxp{sry_no_unicorns}
The rest of this write-up is intended for beginners.
Looking for clues
You start out with a packed PCAP file. So, unpack it and fire up your Swiss Army knife for everything related to network dumps, Wireshark.
This is a forensics challenge, so you should expect the answer to be non-obvious. There is some surfing traffic in there as a decoy. It is mainly surfing web pages about flags on Wikipedia, so the term “flag” should crop up fairly often. Just ignore that. Rather, have a look at the “Protocol Hierarchy Statistics” in Wireshark.
About 64% of the traffic is RTP data. Wireshark can handle that: [Telephony] → [RTP] → [Show all Streams …] will show you exactly one stream. Sadly, my Wireshark cannot playback or extract the data as an audio file. However, you can select the stream, hit [Analyze], then [Save payload…] to get the raw data.
Getting at the audio
The extracted audio is the raw data without a header. RTP payload can have various formats, compressed and uncompressed. The actual format of the data is:
PCM 44100Hz, 16bit signed, big-endian, stereo, uncompressed with interleaved channels
… or put another way: Uncompressed WAVE. There are several ways to figure out the format:
- The connection is setup via RTSP. Filter accordingly in Wireshark: Right
click on [Real Time Streaming Protocol] → [Apply as Filter] → [Selected] in
the “Protocol Hierarchy Statistics” window. Right click on any of the
filtered packets → [Follow TCP Stream]. The format is defined in the
following payload field:
a=rtpmap:10 L16/44100/2. - Wireshark’s stream view says: “16-bit audio, stereo”.
- Do a rough calculation: The dump lasts for about 159 seconds, the RTP data is 28MB. Uncompressed 44100kHz 16bit audio has: 159s * 44100Hz * 2B = 14 MB. So it is likely uncompressed, and a stereo track (x2). Otherwise it would be much smaller.
- You could just guess that it is 44100Hz or 48000Hz, 16bit signed, mono or stereo. Those are the most common audio formats (CD and DVD audio).
If you guess 48000Hz instead of 44100Hz, it won’t matter, you just get a slight pitch shift. If you guess little-endian instead of big-endian, the “music” will be very quiet and overlaid by a very loud noise.
We will use Audacity to work with the audio. Audacity can directly import raw data, just give it the parameters we worked out. Alternatively, you can also put an audio header to the front of the data. I decided to cook some WAVE header, because it is a pretty cheap format, but has a very cheap header. Just remember to use the Big Endian variant (Google for it). This will yield a somewhat broken file:
xxd -r <<EOF >header-be.wav
00000000: 5249 4658 0100 0000 5741 5645 666d 7420 RIFX....WAVEfmt
00000010: 0000 0010 0001 0002 0000 ac44 0002 b110 ...........D....
00000020: 0004 0010 6461 7461 ....data
EOF
cat header-be.wav audio.raw >audio.wav
Note the RIFX instead of the common RIFF. But really, just import it with
Audacity.
Analyzing cats
Now listen to the audio. Now wipe away the blood. Don’t worry, you won’t need your ears to solve this one.
If you have a trained ear, you might here that on some beats, there is a louder
clack. These are the bits, we are looking for. Otherwise, just look at the
spectrogram using a tool like sox or spek:
sox audio.wav -n spectrogram
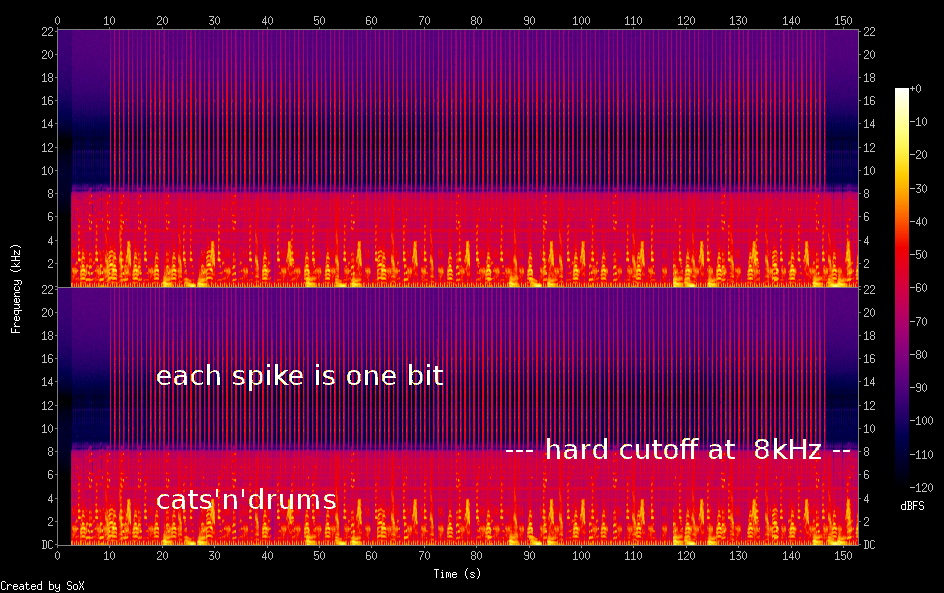
If you know how a spectrum normally looks, you notice immediately those odd-looking needles. The band in the lower third of a channel does not fade out smoothly, but seems to be cut off at 8kHz. That’s the cats’n’drums. The needles contain the “clack” on the beat. Each spike contains one bit of information, and all bits together contain the flag in the following encoding:
8bit ASCII, big-endian
Easy as pie. To get at the flag, we will open the audio in Audacity, and use its “Frequency Analysis”. There is a glaring gap at right above 8kHz:
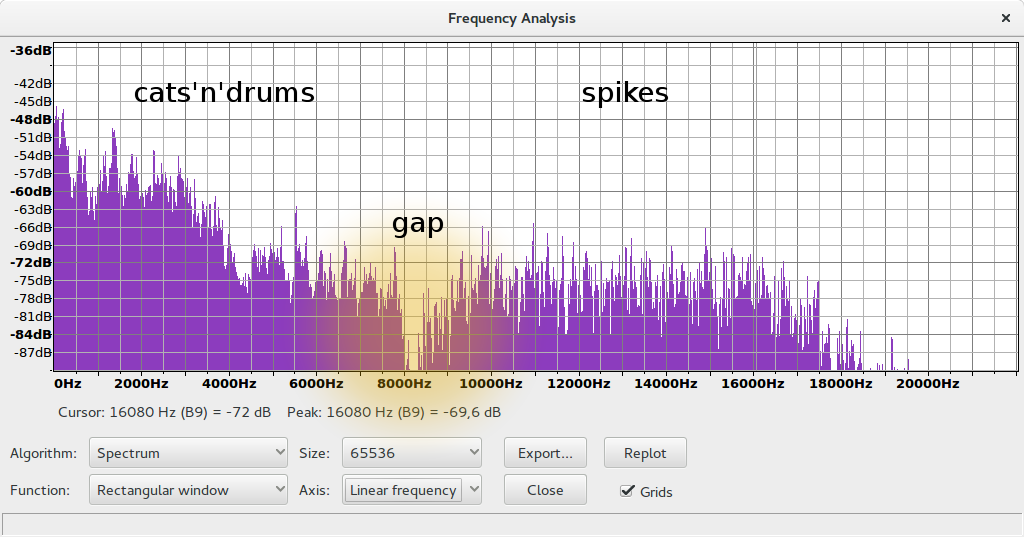
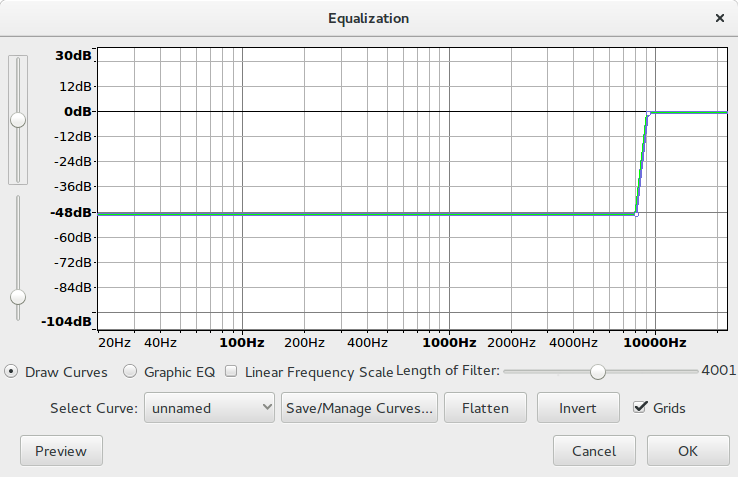
For your convenience, I added a notch filter at 8250Hz to make that frequency interesting to you. But we already had that information from the spectrum. We will now cut out all low frequencies with a very narrow -48dB high-pass filter. You can use Audacity’s Equalization “effect” for that. Our fall-off is between 8kHz and 9kHz. Do not make it too steep, or you may get aliasing which disturbs the high frequencies, the ones we are interested in.
Afterwards, the low frequencies are completely gone. Now look at the amplitude of the audio signal:
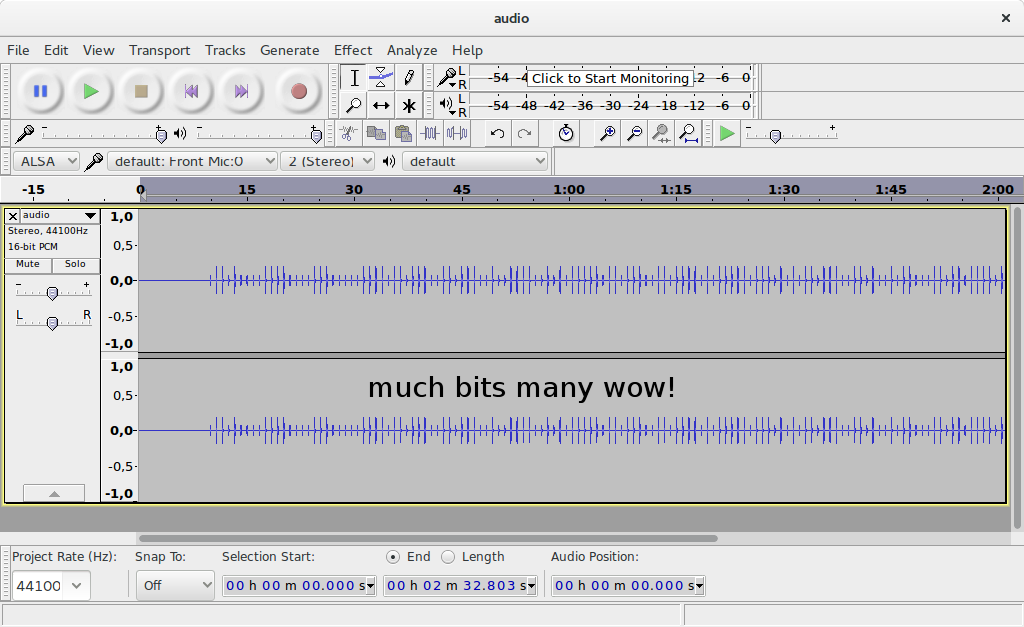
Now look at those beautiful zeroes (low peak) and ones (high peak)! You can write a script to extract the peaks, which is left as an exercise to the reader, or read it out by hand. The bit sequence is:
0110100001111000011100000111101101110011011100100111100101011111011011100110111101011111011101010110111001101001011000110110111101110010011011100111001101111101
Just group it up neatly and translate it to characters in the programming language of your choice (I recommend Haskell):
h x p { s r y _
01101000 01111000 01110000 01111011 01110011 01110010 01111001 01011111
n o _ u n i c o
01101110 01101111 01011111 01110101 01101110 01101001 01100011 01101111
r n s }
01110010 01101110 01110011 01111101
So the flag is: hxp{sry_no_unicorns}
No cats were harmed during the creation of the track, but I cannot comment on the health of the participants of the TUMCTF Teaser.